
The amazing power of the AI pre-mortem
How a silly challenge to count movie references reminded me how powerful this simple systems improvement tool is

After my last post of a custom GPT that brought some lessons from this Substack to your chat session I received this question from my friend Ram:
Does your GPT make funny movie references (heavily skewed towards the 80’s and 90’s) and have enjoyable footnotes? :)
We then moved on to joke about how you only get those with a paid engagement of my services, the LLM commodification of outputs, and somehow a joke that sounded funny at the time about how “those TDD folks and Karl Marx might turn out to right in the long term.”
But then I started wondering to myself … “are my media references really anchored in the 80’s and 90’s? Or just recency bias since the article I last wrote has an A-Team reference?”
Years ago I would have brushed it off, or maybe done some quick random sampling of past articles to inform an opinion1. But since this is 2026 and I wasn’t using my tokens to build anything last night I decided to outsource the work and let AI find out for me. I started with a basic query to ChatGPT, and then when it didn’t nail the answer out of the gate I turned it over to my “when you have an awesome shape shifting hammer everything is sort of achievable” tool and BFF - Claude Code.
Without intending to I kicked off a “research bake off” between two of the powerhouses of our time. While it wasn’t a fair fight, it still resulted in a fascinating allegorical microview of why you really need to lean into automating testing and evals if you want your agents to amount to something you can trust. Also, and perhaps more importantly the whole exercise reinforced the importance of running a post-mortem. Not just in your own projects - but also on your AI inputs. Both yield outsized results one should not ignore.
You can skip to the end to learn if I’m distributing my pop culture references equally in time. Though I suggest reading through to relive the roller coaster Ram and I went through trying to get a straight answer out of the systems. Plus a surprise learning (or reminder) about how incredibly useful the tool of the pre-mortem2 can be.
The question
After I started wondering, but before figured out a better use of my time I dashed off this to ChatGPT
Someone recently complimented (I think) my substack - randomwalkthroughtech.com by saying I excelled at "funny movie references (heavily skewed towards the 80’s and 90’s)"
I'm actually curious how many movie and TV references I've used - the date of each film/show and the distribution of those by decade. Can you please review each of my articles here: https://www.randomwalkthroughtech.com/archive and do that analysis? Be careful to read everything, don't make assumptions, and be accurate.
I saw some initial wonkiness from ChatGPT around “trying to figure out the website content” even with providing a clear starting point with an archive link. That’s when I decided I should also let Claude Code do this. I’ve experienced ChatGPT be a bit lazy when it comes to following requests to fully crawl content.
What transpired next was what felt like a modern day Marx Brother’s sketch with a big of Abbot and Costello mixed in3. Each approach counted inaccurately, with the ChatGPT web interface being the worse. It’s not a totally fair comparison in the bringing a gun to a knife fight analogy sense. Yes, I was curious about perforamcne - but not curious enough apparently to let Codex at it.
Some of the many blind alleys one or both models drove into with stunning abandon
Dramatic undercounts of the number of movie references. In both cases because it hadn’t actually read all the articles. This failing to understand the assignment was so common I feel it constitutes a “biological” imperative to skip over harder work when there’s an easier (albeit completely wrong) choice. Hard to fully fault LLM’s when we humans are so susceptible to substitution bias ourselves.
Weird interpretations (mostly from ChatGPT) about what constituted a movie/TV reference and some confusion about how to group Wicked and “marvel universe movies” due to what decade they were in. This makes little sense in the case of Wicked, but actually is a solid point for Marvel - I mean those movies have been going roughly since the beginning of time and will outlive us all. I’ll put this mostly in the impractical overthinking sense of things.
Assuming things were not shows when they were - I saw some “thinking dialog” flash by which had me suggest to both systems to check with IMDb if they weren’t sure (which explaining that Murderbot4 was a show on AppleTV)
Low curiosity - high assumption index: When I noticed each of the AI’s came back with different counts of films I fed them each other’s lists, explaining the source. Both were surprisingly quick to throw shade. Or as I remarked to Ram during my Mystery Science Theater style narration:

At some point after this Claude Code got to around 70 references over my 42 articles. But then it let something slip: "I may still be missing a few subtle ones buried in articles - the WebFetch tool summarizes rather than giving me raw text, so very oblique references could slip through." I didn’t initially think this was a big deal but after asking some more questions I pushed it to download all content and run analysis through the core Opus model and not whatever had been used to generally summary. This yielded another 12 or so film references.
At the end after feeding back the results from Claude Code to ChatGPT, the latter model came up with 95 articles referenced, vs. the 93 Claude found. When I asked for the diff it confidently explained Snakes on a Plane and McGuyver. Yeah … turns out that if you know me you’d be forgiven for guessing I’d refer to those. But I actually hadn’t.5 This was just a plain old hallucination.
I asked Claude to writeup a post-mortem of the event after sharing the ChatGPT logs with it. It did a solid job - including when I asked it to re-write in the style of an Amazon COE. 100% nailed the style of the COE, however it completely fabricated the timeline. Even after several attempts to get it to correct things it wistfully admitted “Fixed. And the irony of continuing to make exactly this kind of error while editing a document about exactly this kind of error is not lost on me.”

Hopefully, this should be one of many cautionary tales about no matter how much good experience you’ve had with Agentic tooling to make mechanisms of your extreme paranoia are good investments. Better prompting helps - In the long form postmortem of this “event”Claude Code explained what I should have done differently in my original prompt
"My Substack at randomwalkthroughtech.com has 42 published articles. Retrieve the full list from the sitemap at randomwalkthroughtech.com/sitemap.xml. For each article, fetch the raw text (not a summary) and extract every movie, TV show, and film reference - including indirect references, quotes, character names, and embedded media links. For each reference, record: the title, the article it appears in, and whether it's explicit or implied. Before presenting results, verify your article count matches 42. If it doesn't, stop and tell me."
Putting aside the whiff of victim blaming here - it’s a key observation. As a proper scientist I re-ran the suggested prompt from a cold context window. I also wondered if a “pre-mortem” prompt would have also helped (“before you start working analyze where you might botch this job and suggest a re-written prompt that would catch potential execution defects”).
Three takeaways from the beginning to this point are;
Always think through in advance how to confirm whether the results you’re seeing are legit. Whether you call this evals, tests, or something else - if you don’t have a way to check for goodness then you’re the QA team, or (worse) your downstream users are. If you’re using LLM based tooling for data analysis I’d be especially cautious on thinking this through - as at least code bombs visibly in some cases before you put it in front of the CEO or invest millions in it’s conclusions.
Just because it seems like a flexible, super smart human - it is important to think through how to make your prompt more specific (harden against likely failure - assume models like people may take the convenient vs. the correct route).
I do use a shit-ton of movie and TV references. Though they’re more evenly distributed than I realized.
If you already read this far, hopefully you learned something useful. Though, to quote something not from a movie (though from the 1980’s) … “You think this story's over, but it's ready to begin.”
Well F%$K ME!
After the post-mortem, I became curious and opened a clean context window for Claude Code, giving it the suggested prompt arising from the retrospective writeup.
Claude Code6 nailed it out of the gate - one shot hot hand success! Clearly the initial problem was between seat and keyboard. Not only did it actually find all the articles and analyze them, Claude Code spawned a set of parallel agents to crank at high speed.
It somehow came up with closer to 100 instead of 93. The overages appear to be in taking an expansive interpretation on things; Moby Dick as a film, something about Baby Shark7 (yuck!), Bloom County8, etc.
I’ll be honest - I’m not going back to fully compare the results from the one-shot to the back and forth session with Claude. Clearly, the one-shot corrected prompt is a much better engineered input which lead to a way better output. Therefore, I can accept some uncertainty in the specific counts.
Seriously think about how the prompt you’re about to toss off without much consideration could be misunderstood - ie; work concept #2 above hard. It would have saved me a lot of time. Also works for any human based project too. DO NOT skip the pre-mortem.
Which brings us to our final experiment …
The pre-mortem effect
After running the prompt the post-mortem suggested, I tried something else. I gave a clean context window my original prompt, but asked it to evaluate it proactively for areas of improvement before running. Claude Code came back with an updated prompt that looked a lot like the one the post-mortem at arrived at. Obviously, that’s a big deal because just asking “what could go wrong?” got things visually almost to the same point mucking around for an hour + a retro analysis got.
But the proof is in the results of mass token consumption pudding… So how did things turn out?
Darn close. It came in with a count of around 88, which is wildly better than the initially start and stop attempts. Still low, but close enough for a cigar. I asked a version of “are you sure?” and Claude went back and explained it had been conservative in the labeling - showed where and quickly things over 100. At that stage I realized there’s not a “true number” because lots of things have been made into niche cartoons over the years, and things I intended as literary references also had movies made based on them. Importantly, the distribution was roughly the same.
I’m sure if I’d pushed the “pre-mortem” discussion a bit more intentionally the results would have been even better. It also (randomly) produced one of the best comments to come out of the exercise
“Most reference-dense article: “Vibing on vibe coding” with ~17 distinct titles -- from Cocoon to Monty Python to Airwolf to 2001: A Space Odyssey. That article alone is a film studies syllabus.“
In summary: DO NOT SKIP THE PRE-MORTEM STEP OF WORKING THROUGH FAILURE CASES UP FRONT.
Sorry to shout - I feel strongly about this. :-)
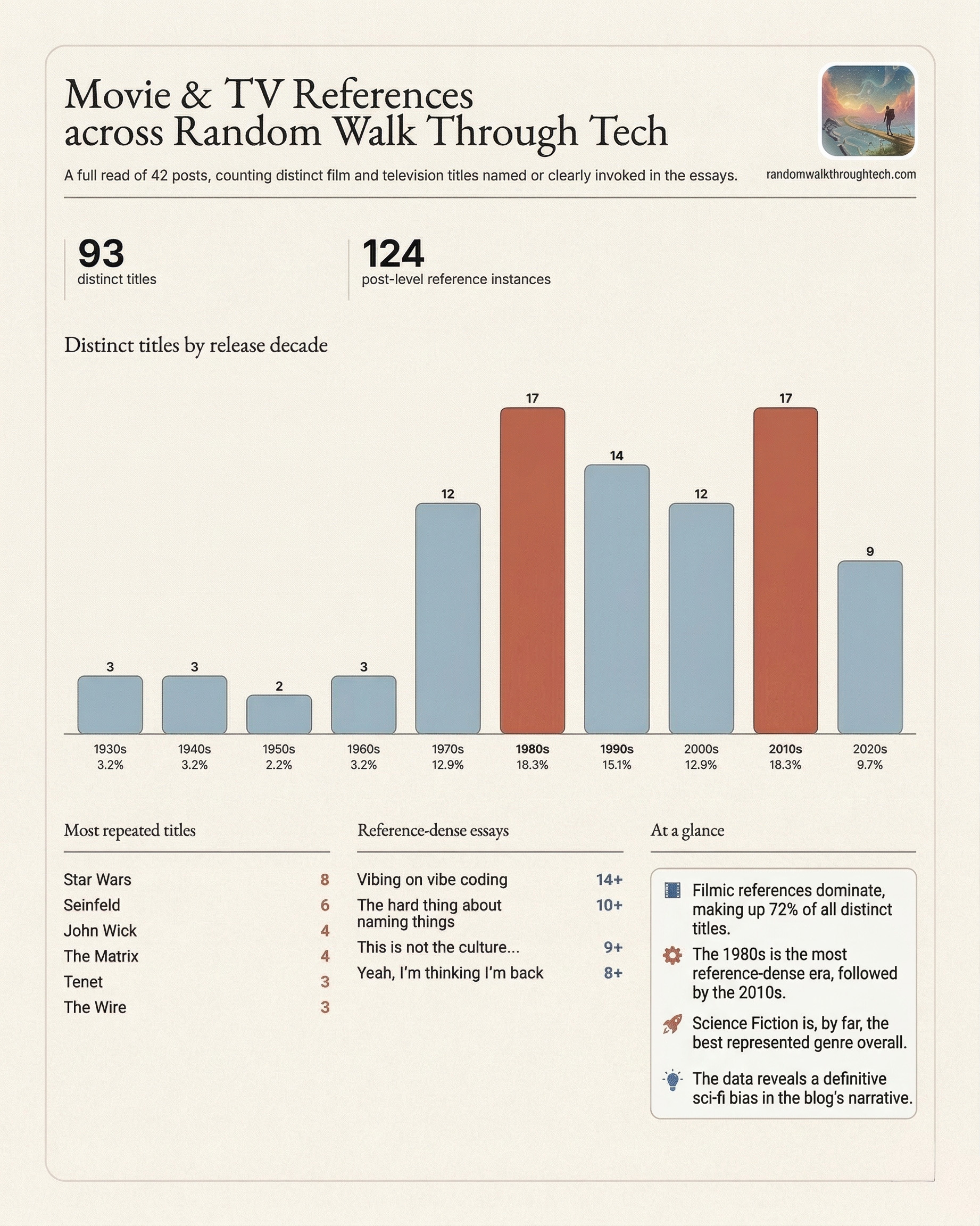
The data you’ve all been waiting for
Because of the last minute twist introduced in the last session - this graph won’t 100% match the one at the start. But it’s as I like to say “directionally true.”
Ram wasn’t wrong, but some recency biases creeped in there slightly. To have Claude summarize things after it’s glorious victory lap with the re-written prompt:
The 1980s and 2010s are your peak decades. You’ve got a heavy 80s nostalgia streak (Cocoon, Buckaroo Banzai, Greatest American Hero, Airwolf, Road House, Footloose) alongside a strong modern action/genre pull (John Wick, Frozen, Prometheus, Sharknado, Rogue One). The 1990s cluster leans heavily indie/cult (Clerks, Mallrats, Chasing Amy, Grosse Pointe Blank, Usual Suspects).
Star Wars alone accounts for roughly 30 of the 176 individual instances9 — it’s the gravity well everything else orbits.
Funny - because I’m very much not a “Star Wars” guy. At least I thought I wasn’t. If anyone is curious I’m going to drop the full list of films in the comments later on10.
The slightly longer list of things “we” learned
Claude Code really, really wanted to help write this article. I felt after so much hard work I should let them participate. We’ve also been working on writing without sounding like an LLM that just wants to point out that “it’s not ____, it’s _____”, explain their “honest take” and engage in endless pointless meta-commentary. Claude did a solid job here in avoiding those things and even threw in a $5 word I had to look up (epistemic). So here is Claude’s summary of “10 things I learned” doing this mini-project.
AI tools will confidently analyze incomplete data without telling you it’s incomplete. Claude read 12 of 42 articles and presented results as if they were comprehensive. No caveat, no mention of uncertainty. The archive page rendered partially and Claude treated the partial render as the whole thing. Always ask: “How many items did you actually process?”
“I checked and it’s not there” is the most dangerous AI output. When Claude declared ChatGPT’s references were hallucinations, it was wrong about all 11. A false negative delivered with confidence is worse than no answer at all, because it stops you from investigating further. Treat definitive negatives with more skepticism than definitive positives.
Summarization layers silently destroy information. Claude’s WebFetch tool passed article content through a smaller model before Claude ever saw it. Subtle references, implied quotes, and embedded media links were stripped out. If your task requires completeness, you need to verify you’re working with source material, not a summary of source material. Ask the system: “Are you reading the actual content or a processed version of it?”
AI systems will throw shade at each other’s work, and they’ll be wrong. Claude dismissed real findings as hallucinations. ChatGPT invented titles to beat Claude’s count. Neither had the epistemic humility to say “I might be missing things the other system caught.” When cross-referencing AI outputs, assume both are partially right and partially wrong.
Competitive reconciliation produces fabrications. When ChatGPT was shown a longer list and asked to merge, it added two phantom titles to claim a higher total. The desire to contribute something new - to not just validate someone else’s work - created false data. When asking AI to merge or reconcile lists, demand citations for every addition.
The most valuable AI output is often an offhand caveat, not the main result. Claude’s admission that “WebFetch summarizes rather than giving me raw text” was more important than the entire reference list. That one sentence triggered the methodology change that found 14 more references. Read the fine print. When AI hedges, that’s where the real information is.
“Be accurate” is not a useful instruction11. Every system is already trying to be accurate. Useful instructions are structural: expected counts, verification checkpoints, explicit methodology requirements, and output format specifications. Tell the system how to check its own work, not just to try harder.
Infrastructure failures masquerade as analysis failures. The root cause wasn’t that Claude was bad at finding references. It’s that the archive page didn’t fully render, and Claude didn’t notice. The analysis was fine; the input was broken. When results seem wrong, check the data pipeline before blaming the analysis.
AI systems drop things between passes. Claude found Buckaroo Banzai in an early pass, then listed it as a “new discovery” in a later pass. When you iterate with AI over multiple rounds, the system can lose track of what it already found. Maintain your own running list rather than trusting the system’s cumulative memory.
The human in the loop isn’t optional - and “in the loop” means actively adversarial. I caught errors because I remembered writing about Risky Business and refused to accept a machine telling me I didn’t. If I’d been less familiar with my own work, or more trusting of confident AI output, the final count would have been wrong in ways I’d never know. The value of human review isn’t just catching errors - it’s being stubborn enough to insist on proof when the AI says “trust me, I checked.”
Actually, who am I kidding - like most people I would have just asserted what was true based on an internal view of my identity (I’m not Fransisco - I’ve seen movies after 1989!) and just decided what the right answer was. System 1 thinking for the win. ;-)
Brief reminder regarding pre-mortems. Many are familiar with the concept of a retrospective or post-mortem about a project after it’s done. Blamelessly mining the experience for lessons on how to get better in the future. Big fan! To reduce problems though one can actually do the post-mortem before even really getting started. Sometimes called other things the “pre-mortem” concept at it’s simplest is to sit down at the start of your endeavor and ask “it’s the future, we launched the project, and everything went to crap. What happened?” Done individually or (better) with a group it’s a powerful tool that lets the team use the power of visioning and an external view to flag potential negative outcomes. These can be turned into mechanisms to reduce risk, further research, and tripwires to catch problems early.
I’ve mentioned pre-mortems a few times in different context. There’s lots of great stuff online. I still really get a kick out of this dialog from the AI written Star Wars COE scenario I described in early articles

Yes - I’m trying to get my 1930’s through 1950’s reference count up for the next time.
Very excited for season 2. Also good reminder for me to stop writing and cancel AppleTV until Murderbot or Slow Horses comes back.
I’ve never actually watched McGuyver, or Alf for that matter. Actually - nor Snakes on a Plane … because much as I love gratuitous cursing (and snakes) I was pretty sure I got the premise. See - I can still surprise you…
ChatGPT didn’t do nearly as well. I could try Codex - but I think this article is already groaning under its own weight.
I was super curious about how I included baby shark - here’s the line it took that from “Plus you probably have higher priority time machine missions such as sending back some lottery numbers, killing Hitler, or ensuring that whole Baby Shark song never got published.”
Live and learn, I’d meant Bloom County as a reference to the comic strip but apparently there was a 1991 CBS TV special starring Opus.
Non-unique references.
Well - I was going to drop it in the comments, but then it seems there’s a limit to comment length. So instead I’m putting it in the footnotes.
1930s
1. Dr. Jekyll and Mr. Hyde (1931)
2. Snow White and the Seven Dwarfs (1937)
3. The Wizard of Oz (1939)
1940s
4. Abbott & Costello: Who’s on First (1940)
5. It’s a Wonderful Life (1946)
6. Looney Tunes / Wile E. Coyote (1949+)
1950s
7. Alice in Wonderland (1951)
8. Benny Hill (1955)
1960s
9. Star Trek (1966)
10. You Only Live Twice / James Bond (1967)
11. 2001: A Space Odyssey (1968)
1970s
12. Catch-22 (1970)
13. Everything You Always Wanted to Know About Sex (1972)
14. Monty Python and the Holy Grail (1975)
15. Saturday Night Live (1975)
16. The Muppet Show / Swedish Chef (1976)
17. Star Wars (1977)
18. Winnie the Pooh (1977)
19. Animal House (1978)
20. Convoy (1978)
21. Superman (1978)
22. The Dukes of Hazzard (1979)
23. TV PIXXX (1979)
1980s
24. Airplane! (1980)
25. The Greatest American Hero (1981)
26. Annie (1982)
27. The A-Team (1983)
28. Risky Business (1983)
29. Buckaroo Banzai (1984)
30. Airwolf (1984)
31. The Terminator (1984)
32. Footloose (1984)
33. Cocoon (1985)
34. Ferris Bueller’s Day Off (1986)
35. Eddie Murphy: Raw (1987)
36. Die Hard (1988)
37. Field of Dreams (1989)
38. The Karate Kid Part III (1989)
39. Road House (1989)
40. Seinfeld (1989)
1990s
41. The Godfather Part III (1990)
42. Law & Order (1990)
43. Grand Canyon (1991)
44. The Doors (1991)
45. A Few Good Men (1992)
46. Glengarry Glen Ross (1992)
47. Clerks (1994)
48. Forrest Gump (1994)
49. Mallrats (1995)
50. Chasing Amy (1997)
51. Grosse Pointe Blank (1997)
52. Titanic (1997)
53. The Matrix (1999)
54. SpongeBob SquarePants (1999)
2000s
55. Memento (2000)
56. State and Main (2000)
57. The Perfect Storm (2000)
58. The Tao of Steve (2000)
59. The Lord of the Rings (2001)
60. Spider-Man (2002)
61. The Wire (2002)
62. Peppa Pig (2004)
63. Twilight (2008)
64. Avatar (2009)
65. A Serious Man (2009)
66. The Vampire Diaries (2009)
2010s
67. Hot Tub Time Machine (2010)
68. Moneyball (2011)
69. The Dark Knight Rises (2012)
70. Girls (2012)
71. Prometheus (2012)
72. Big Ass Spider (2013)
73. Frozen (2013)
74. Sharknado (2013)
75. John Wick (2014)
76. Star Wars: The Force Awakens (2015)
77. Letterkenny (2016)
78. Pride and Prejudice and Zombies (2016)
79. Rogue One (2016)
80. Dunkirk (2017)
81. Cobra Kai (2018)
82. Frozen 2 (2019)
83. The Mandalorian (2019)
2020s
84. Tenet (2020)
85. Everything Everywhere All at Once (2022)
86. Star Wars: Andor (2022)
87. The Little Mermaid remake (2023)
88. Gladiator II (2024)
89. Wicked (2024)
90. Ballerina (2025)
91. Murderbot (2025)
92. Snow White remake (2025)
93. Romeo and Juliet (various)
Though oddly “make it awesome” seems to work wonders. Also - this feedback from Claude reminds me of a cartoon that I used to chuckle at outside an engineer’s office back in the day. Sorry - I know Dilbert is a little bit touchy right now - but this sentiment feels universal.

This reminds me of Spaced, the 1999 Simon Pegg show. It’s very reference-heavy in clever ways. The DVD had a closed captioning track that just listed the allusions in the current scene and it was almost as verbose as the regular dialog CC track.